任务成功(task success)可能是使用最广的绩效度量。它测量的是用户能在多大程度能有效地完成一系列既定的任务。
1. 测量任务成功的方法
为了测量任务成功,要求参加者操作的每个任务都必须有一个清晰的结束状态,比如购买产品、找到特定问题的答案或完成在线申请表。
在实验室可用性测试中,测量任务成功最常用的方法是让参加者在完成任务后进行口头报告式回答。收集任务成功的另一个途径是让参加者以一种更为结构化的方式进行回谷,比如使用在线工具或纸制的表格。每个任务可以有一组多选项,参加者可以从四到五个干扰项中选择一个正确的答案。
2. 二分式成功
二分式成功是测量任务成功的最为简单和常用的方法。参加者要么成功完成了任务,要么没有成功。这与大学里的“通过/未通过”的课程是一个类型。当产品的成功取决于用户完成某一个或某一组任务时,用二分式成功是合适的。接近成功不管用,唯一重要的是用户能成功地完成他们的任务。
(1)如何收集和测量二分式成功
用户每操作一个任务,都应给予一个“成功”或“失败”的得分。通常这些得分以1(表示成功)或0(表示失败)的形式出现。有了数字得分,你可以很容易地计算出操作的平均值及其需要的统计值。除了给出均值以外,最好也包括置信区间,使之作为二分式数据的一部分。
样例图:如何组织二分式成功数据。置信区间是在基于二项式分布而算得的。
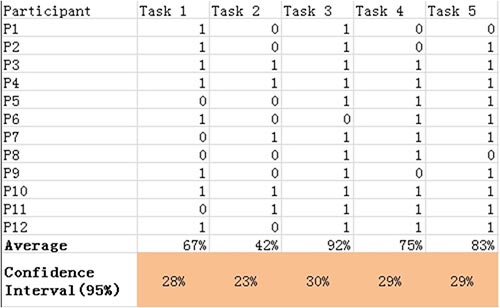
(2)如何分析和呈现二分式数据
按任务来分析和呈现二分式成功率(binary success rates),这是最常见的方法,这包括简单呈现成功完成每个任务的参加者百分数。当你想比较任务之间的成功率时,这种方法最为有用。通过查看特定问题以确定需要什么样的改进来解决这些问题,你可以在后续进行更为详尽的分析。如果你有兴趣了解不同任务之间是否存在显著性的差异,你将需要进行t检验或方差分析(ANOVA)。
从用户角度查看,二分式成功数据的主要价值在于:可以区别不同组别的用户,他们操作的方式不同或碰到不同类别的问题。这里有一些区分不同参加者的常用方法:
- 使用频率(经常使用的用户和不经常使用的用户)
- 使用产品的已有经验
- 专业领域
- 年龄组
样例图:如何呈现每个任务的二分式成功数据。误差线表示的是95%置信区间(基于二项式分布)
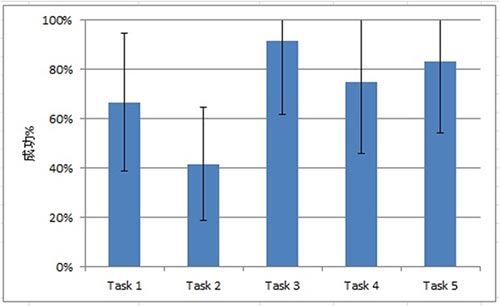
如果在可用性研究中你有相当多的测试参加者(至少是12个,理想情况下超过20个),把二分式成功数据呈现为频次分布是比较有用的。对于以视觉化方式表示二分式任务成功数据中的差异来说,这种方法比较方便。
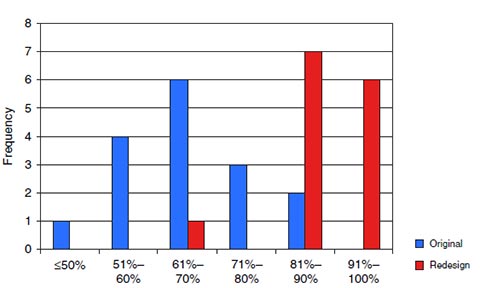
例如在上图中,有6个参加者在初始网站的评估中成功完成了61%到70%的任务,1个参加者完成率小于50%,2个参加者完成率在81%到90%之间。在重新设计后的网站评估中,有6个参加者的成功率在91%及以上,没有参加者的成功率低于61%。上图几乎没有重叠地表示出了两个任务成功率,与仅仅报告两个平均值相比,这是一种更能表示设计迭代之间是否有提高的方法。
(3)计算二分式成功数据的置信区间
分析和报告二分式成功数据最为重要的方面是包括置信区间。在大多数可用性研究中,二分式成功数据基于的样本都比较小(如5-20个参加者)。因此,二分式成功度量可能不如我们所期望的那样可信。
二分成功率本质上属于比例数据:成功完成既定任务的参加者比例。计算置信区间最合适的方法是用二项式置信区间:wald方法和exact方法。其中校正后的wald方法可产生较好的结果。
Jeff Sauro在其网站上提供了一个非常有用的计算器,可以用它来确定二分式成功的置信区间:http://www.measuringusability.com/wald.htm。当输入尝试完成既定任务的参加者总数及成功完成该任务的参加者数量之后,这个工具就可以自动进行平均任务完成率的Wald、校正的Wald、Exact和Sore运算。可以选择计算99%,95%或90%的置信区间。对于置信区间来说,大的样本量总是能够产生小的(或者说更为准确的)区间。
3. 成功等级
当任务成功的数据存在一些合理的灰度地带时,可以对成功程度进行等级划分就很有用。参加者会从部分完成某项任务中获得某些值。可以把它想象成为完成家庭作业可以获得部分学分一样,即:如果你能展示了你的工作,即便存在一些错误的回答,你也能获得一些学分。
(1)如何收集和测量成功等级
就成功等级而言,有3个方面的观点:
- 成功等级可以基于参加者完成任务的程度来评定。这可以通过参加者有没有获得什么帮助或者是不是只部分做了回答等角度予以确定。
- 成功等级可以基于参加者完成某任务过程中的体验来评定。有些参加者需要付出不少努力。而有的参加者可以没有困难地完成他们的任务。
- 减功等级可以基于参加者完成任务的不同方式来评定。有的参加者可以以一种最优的方式来完成任务,而有的参加者完成任务的方式却不是最合适的。
基于参加者完成某任务的程度而设定的任务成功在3到6个等级数量之间是比较典型的做法。更为常用的方法是采用3个等级,即1=完成任务,0.5=部分完成任务,0=失败。按照是否需要帮助,3等级扩展为6个等级:
- 完成成功
— 需要帮助
— 不需要帮助 - 部分成功
— 需要帮助
— 不需要帮助 - 失败
— 参加者认为完成了,但实际上没有
当测量成功等级时,一个普遍的问题是要确定给予参加者什么样的“帮助”。下面是一些我们确定为要提供帮助的情境样例:
- 测试主持人让参加者返回到首页或重皿到初始(任务之前)状态。这种形式的帮助可以使参加者适应测试情境,有助于避免一开始就会导致某些困感的特定行为,
- 测试主持人询问一些探查性问题或重新设定任务的状态。这可以使得参加者以其他方式考虑其操作行为或选择。
- 测试主持人回答一些问题或提供一些信息以帮助参加者完成任务。
- 测试参加者从外部资源寻求帮助。例如,参加者给代理商打打电话、使用某些其他网站。查询用户手册或打开在线帮助系统。
成功等级也可以根据用户的体验进行评定。通常我们会发现,有些任务完成起来没有任何困难,而其他有些任务完成起来总一直会有一些或小或大的问题。区分这些不同体验是重要的。一种4点赋分的方式可以用于对每个任务进行成功等级的确定:
1=没有问题。
2=小问题。
3=大问题。
4=失败/放弃。
当使用这种赋分系统时,要记住这些数据是顺序数据,这一点比较重要。所以不应该报告一个平均得分,而是对每个完成等级都可以把数据呈现为频次分布。
根据参加者所给出的不同回答是组织成功数据等级的另一种方法。例如,你可以根据参加者回答的质量,给一个最优的答案赋予1.0的得分、给可接受的回答(但不是最佳的)赋予0.75或0.5的得分。你不一定要赋予一个数字得分,但是如果你想做进一步分析的话,那样数字分数会更方便些。同样,这也适用于为获得某特定答案而使用的不同导航策略。如果你正在评价一个网站,有时参加者点击了最合适的链接,且没有任何问题就能完成任务。而有时参加者点击了次优的链接、但最终页还是成功地完成了任务。
(2)如何分析和呈现成功等级
在分析成功等级时,首先要做的是绘制一堆条形图。这可以表示出不同类或等级上(包括失败情况)的参加者百分数。要务必确保条形图加起来是100%。下图是表示成功等级的常用样例。
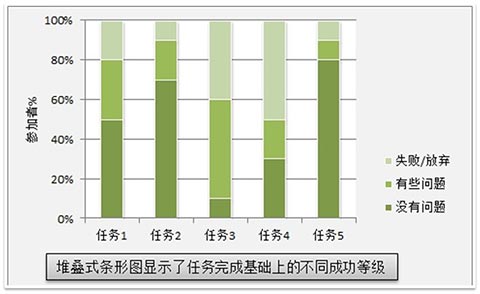
4. 测量任务成功的问题
在测量任务成功过程中有一个重要的问题,是如何简洁地定义一个任务是否成功了。其关键是,提前就要清晰地定义好成功完成每个任务的标准是什么。把对于每个任务中可能会出现的各种情况都要考虑周全,进而确定它们是否促成了成功。例如,如果参加者找到了正确的答案但却以错误的形式报告出来,这种情况下任务是不是也成功了?如果参加者报告了正确的答案但接着再表述其回答时却不正确了,这又做何处理?
在可用性评估中经常出现的一个问题是:如果参加者没有成功完成任务的话,该如何或何时结束一个任务?实质上,这是对于不成功的任务如何设定“停止规则(stopping rule)”的问题。这里是一些常用的方法,可以用来结束不成功的任务:
1、在测试单元开始的时候就要告诉参加者,应一直操作每个任务直到完成或处于某个节点(实际中,往往是参加者放弃或向技术支持、同事等求助的时候)时为止。
2、采用“事不过三”的规则。其意是在你停止参加者继续操作之前,他们还可以有三次尝试完成某任务的机会。
3、超过了事前设定的任务时间,就“叫停”任务。
转载请注明:陈童的博客 » 在可用性研究中测量任务成功



