六西格玛(Six Sigma)是一种关注于衡量质量改进的企业研究方法。西格玛(Sigma)指的是标准差,因此六西格玛指的就是六个标准差。在生产制造流程中,六西格玛就相当于每生产1百万个部件就有3.4个次品。作为改进流程的方法,六西格玛最初来源于摩托罗拉的Bill Smith。之后很多公司都采用了这种方法,也出现了很多有关这一主题的书籍。
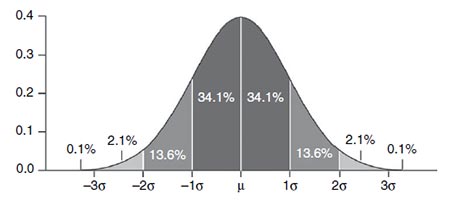
上图说明了六西格玛的基本概念。在平均数上下的三个标准差(σ或西格玛)范围内,能解释99.7%的事例。只有0.3%的事例超出了这个范围。六西格玛的基本目标就是要达到这样的质量水平:所处理的任何事情犯错的概率都仅为0.3%或更低。
那么如何将其应用于可用性数据呢?在这里所讨论到的任何度量都能够计算它的西格玛值(比如任务完成率、时间。错误和满意度)。对于如何在可用性度量中应用六个西格玛,至少有这样一种理解,即:经过几次迭代,设法在可用性度量上获得提升。也就是与刚开始相比至少要高出(好于)三个标准差。但对可用性数据来讲这是否可能呢?
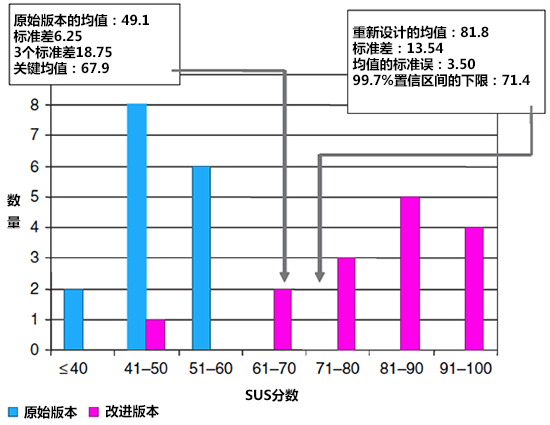
上图中的数据来自于LeDoux、Mangan和Tullis(2005年)的数据,他们报告了对一个内部网站两次可用性测试的结果:原始版本和改进版本。上图列出了这个站点两个版本的平均SUS得分的分布情况,原始站点的平均SUS得分是49.1,标准差是6.25,标准差的三倍是18.8,这意味普要超越“关键的平均SUS得分”,需要高于49.1+18.8 =67.9分。改进站点的平均SUS得分是81.8,标准差是13.54。平均数的标准误(standard error)是3.50,这意味着在99.7%置信区间内均值的下限是71.4。因为即便是改进版的下限也要高于原始版本的关键平均值(67.9),所以就可以说新设计在SUS评分上获得了六个西格玛的提高。
转载请注明:陈童的博客 » 可用性的六西格玛改进