元数据是指信息的信息。元数据是所有组织系统的基础,从搜索到购物网站上的分面导航系统都依赖于元数据。信息可以有多种不同形式,可以是一篇文章、一本电子书、一张照片或者是一个目录。有些信息没有文字,如Flash影片、MP3格式的声音或者照片。如果信息中固有的文字很少(比如照片和音乐就是如此),那么元数据将有助于这些信息的查找。
元数据就是关于每一项内容的所有信息。例如,对于一首歌曲,元数据可能包括:“Brown Sugar,第2版,花絮,作词作曲分别是Mick Jagger和Keith Richards,演唱者为滚石乐队,唱片名为Itchy Fingers, bootleg,时长3分50秒,分类是摇滚乐,蓝调布鲁斯”……
如今,常用的3类主要元数据包括:
- 固有性元数据:与事物构成有关的元数据。JPEG图片、20KB大小。
- 管理性元数据:与事物处理方式有关的元数据。文档的编辑是谁?已经获准发表了吗?
- 描述性元数据:与事件本质有关的元数据。是Web上最常用的元数据。这篇文章的主题是什么?相关主题是什么?

上图包括的元数据:
固有性元数据:20KB、JPEG格式(说明这个物品是什么)
管理性元数据:摄影师:Noel Franus 。用途:圣诞卡(说明它的用途是什么)
描述性元数据:狗、小狗、犬科、金毛拉布拉多猎犬、金毛拉布拉多犬,圣诞帽,圣诞老人,圣诞节,圣诞,照片,可爱,伤感,让人想抱的(可以这样来描述这个物品)
如果开发过网站,就会接触到HTML的meta标签。例如Dean and DeLuca网站的meta标签中给出的描述元数据:
<meta name=”description” content=”Dean and DeLuca gourmet food stores. Offering a wide selection of California wines, custom gift baskets, cakes, cheeses, hard to fi nd spices, coffee, caviar, truffl es, holiday and seasonal foods.” />
<meta name=”keywords” content=”dean; deluca; gift; gourmet; food; online; store; caviar; cheese; steak; coffee; holiday; artisan cheeses; artisan cheese; spices; california; napa valley; baskets; corporate sales; olive oil; vinegar; chocolate; seafood; shellfi sh; wine; herbs; cooks tools; cookware; cake; cakes; wines; cookies; pies; truffl es; seasonal; bakery; salmon; shrimp; lobster; gifts; balsamic” />
在HomeBistro.com上,可以看到以下管理性元数据:
- <meta name=”ROBOTS” content=”ALL”>
- <meta name=”revisit” content=”15 days”>
- <meta name=”robots” content=”index,follow”>
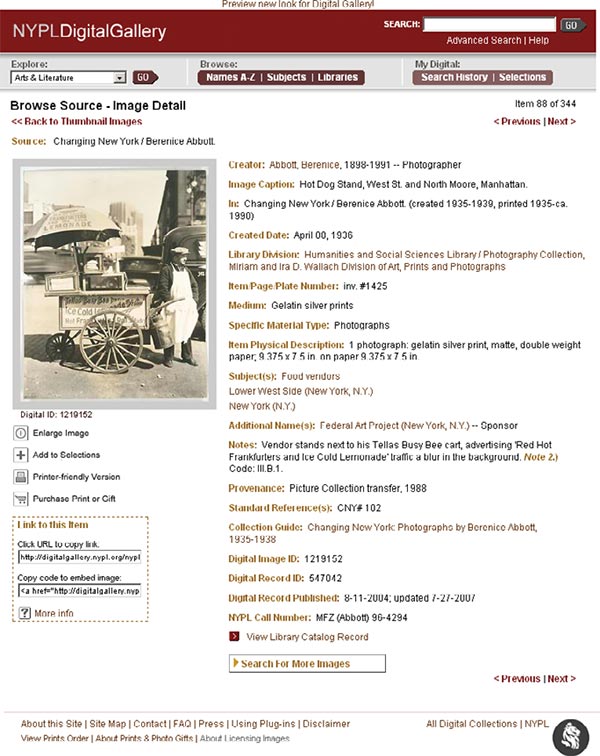
美国纽约公共图书馆(New York Public Library,NYPL)收藏了自发明照相机以来的各种照片,存储空间达57TB。元数据有助于在这个照片的海洋里找到想看的照片。例如,右键照片,查看它的属性就尅看到这些元数据:这是一个JPEG照片,大小303.29KB,609×760像素。

但是知道这些信息对于希望再次找到照片几乎没有什么帮助。描述性元数据可能是搜索和浏览时最重要的信息,因为人类容易记住故事和影像。
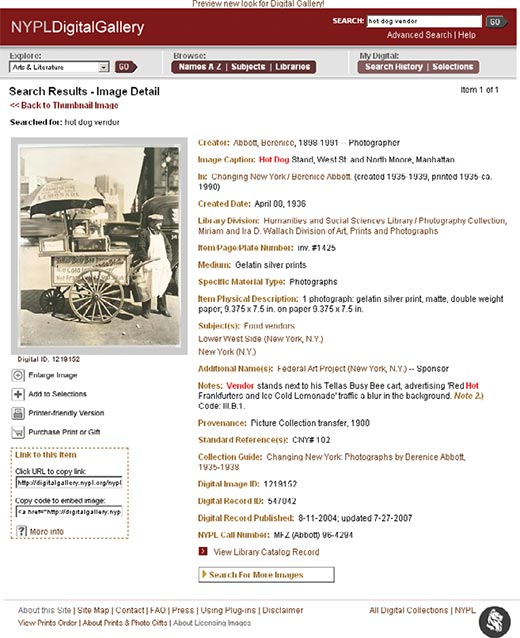
卖热狗的人(West st. North Moore, Manhattan)的有关属性:
1. 可查找性(Findability)
对于大多数人来说,记不住拿破仑是出生在1769年8月15日(出生日期)的法国统治者,也记不住他是二个身高159cm的皇帝。我们所能记住的是,他是一个胳膊上搭着上衣,头戴斜边帽,在征服欧洲大片地盘的同时还在不断向约瑟芬写情书的那个人。那些铁的事实对我们来说黯淡无光,倒是这些充满罗曼蒂克的细节被我们牢牢记住。可以利用人类的这一弱点帮助我们改善“可查找性”。可查找性(Findability)是由Peter Morville创造并普及的一个术语。这是指一个对象能够通过搜索或浏览而被找到的能力。由此可以清楚地看出:要把责任交给要被找到的对象,而不是把负担压在试图建立有效搜索查询的用户身上。
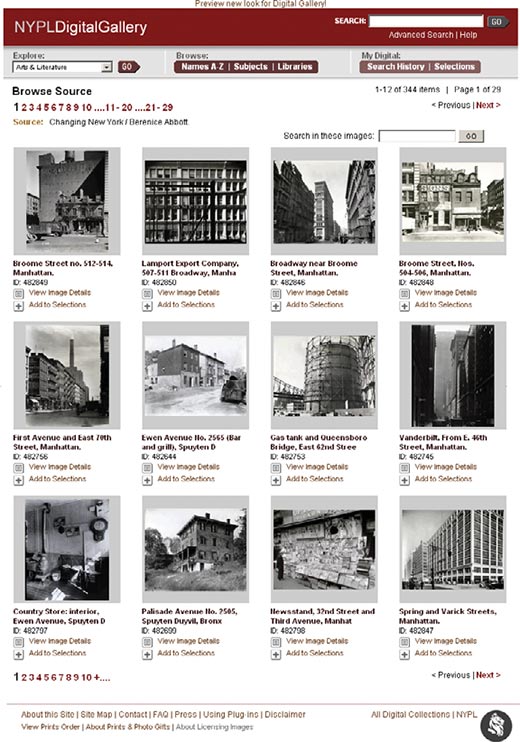
要找到“纽约大街上卖热狗的人”那张照片,用户可以搜索1219152,这是这幅图片的ID号,因为用户记不住,所以一般不会这么做。用户可能会搜索“Bernice Abbott”(摄影师)或者搜索“Changing New York”(这是这个系列的名字)。这些作为搜索项的可能性更大,而且名字比数字更容易记。不过,用户可能会得到很多页的结果。
例如,搜索Beatrice Abbott,会得到图书馆收藏的Beatrice Abbott的所有照片
用户更可能搜索“Hot Dog Vendor”(热狗小贩)。这是描述性信息,它取自于照片所讲的故事,也是照片故事所固有的主题。这些照片创建时并没有故事,摄影师可能会给出一个标题或题目,但对于描述照片的实质内容是不充分的,既然图书馆的任务是允许人们访问“这个世界所累积的精神财富,而不考虑物质财富、信仰、国籍或其他人文条件的差别”,所以图书馆要加入描述以确保能够照片这张照片。主题包括“food vendors”(食品小贩)和“lower west side”(曼哈顿西区底层社会),另外还有一个说明:“Vendor stands to his Tellas Busy Bee cart, advertising ‘Red Hot Frankfurters and Ice Cold Lemonade’ traffic a blur in the background”(小贩站在售货车旁,兜售他的“热腊肠和冰镇柠檬水”,背景中来往的车辆依稀可见)。这些元素构成了一个完整的故事,将与用户搜索时讲的故事匹配。
元数据类型示例
如果手工地增加了元数据,下表中的各项更有可能被查找者找到:
| 对象 | 描述 | 可能的关键字 | 描述性元数据 | 固有性元数据 | 管理性元数据 |
 照片:Santorini教堂 照片:Santorini教堂 |
Santorini(位于Fira城)希腊岛上的一座教堂 | 教堂、小教堂、小路.,希腊、希腊的、Santorini、悬崖、大海、海洋、蓝色.、白色、地中海 | 文件类型:JPEG图像文件分辨率:1600x1200px
文件大小:1814KB |
创建日期:4/20/2012
修改日期:4/22/2012 |
摄影师:Christma Wodtke用途:Greek picture book 2012 |
| 原创歌曲:Ain’t nobody here but us chickens | 随兴创作的即兴歌曲,闲散风格。 | 爵士乐、闲散风格、男性歌手、Mark Murphy、顽皮的、即兴而作、休闲音乐、幽默、糟糕、娱乐、聚会音乐 | 文件类型:MP3
文件大小: 2234KB |
节奏:慢板 | 演唱者:Mark Murphy创作者:Mark Murphy
制作:Mark Murphy |
 防滑条 防滑条 |
就像为脚下安上了汽车轮胎的防滑链,这种便于安装的防滑条让穿着者在冰雪中也能大步前进 | 鞋配件、皮靴配件、防寒装备、防雪装备、防滑、滑、冰、雪,防雪鞋,防雪靴、轮胎防滑链、金属、橡胶、交织 | 制造商:Hammacheer | 库存:有货 | 出品:2012 |
| Adobe InDesign教程 | 使一个Adobe Photoshop文件的透明度不变,为对象和文本应用阴影,混合向量图片和位图图片之间的颜色来达到有趣的效果 | Adobe、InDesign、透明、阴影、文本、向量处理、教程、学习、电子教程、在线学习、flash影片 | Flash教程,布局中使用透明效果 | Flash影片Windows:2.6MB
Flash影片 Macintosh: 3 .6MB |
支持:InDesign2.0 |
| 网站:Common Ground:一种面向人机界面设计的模式语言 | 研究报告,解释如何使用模式来设计交互式系统 | 设计、网站设计、交互设计、交互式、模式语言、Christopher、Alexander、内容表示、导航设计、HTML | 283KB | www.mit.edu/~jtldwell/common_ground.html | 作者:Jenifer Tidwell最后修改日期:
May 17,1999 版权:1999 |
语言是灵活且强大的,同样的事物有很多种表达方式,例如英语中开胃菜可以使用的词汇包括:starter、first course、appetizer或者从其它语言借用的词汇Hors d’ oeuvres、Anamuse-guieule。如果在真实情景下还有解释的机会,而在Web上则没有解释的机会了,所以需要创建一个受控词汇表。
2. 受控词汇表
受控词汇表(controlled vocabulary)就是一种控制所用词汇含义并跟踪相关词的方法。在对开胃菜这个词的优选术语是“first course “,而客人们可能用到的词包括“starter、first course、hors d’oeuvres和appetizer”,可谓多种多样。
受控词汇表有多种不同类型,可能是由等价关系构成的简单词汇表:“对,gravlax和cured salmon是一样的。”也可能是一个复杂的辞典:“gravlax是一种蛙鱼,等同于cured salmon,这是百吉圈和熏鲑鱼的一种配料。”
等价关系
最简单的受控词汇表是一组等价关系:cured salmon和gravlax对于搜索来说含义相同。这种关系可以很简单,例如cat和kittycat(猫)、Lion与lyon(狮子)。这些都认为是一种变体,拼写可能稍有差别,但对于搜索而言,结果是一样的。
等价关系的示例
| 优选词语 | 变体 |
| Smoked salmon(熏鲑鱼) | Fish, gravlax, lox, cured salmon, smoked fish, preserved fish, nova |
层次关系
分类系统是一种更复杂的受控词汇表。除了等价关系外,它还显示了层次关系。
层次关系示例
| 优选词语 | 变体 | 父词(广义词) | 子词(狭义词) |
| Smoked salmon | Gravlox, loxCured salmon | Fish,smoked fish,cured meats,preserved fish | Smoked salmon flatbread with creme fraise,linguini with smoked salmon and asparagus |
关联关系
关联词就是同属一个范畴但却并不相同的一些词,而且这些词也不是更广义或更狭义的词。并非简单地写作“她说”(said),利用分类辞典,你可以写为:她大声叫嚷(yelled),她讲(spoke),她低声耳语(whispered),她旁敲侧击地暗示(insinuated) ,她明白地说(articulated ),她说出(uttered) ,她坚持说(insisted)等等。
分类词典雏形
| 优选词语 | 变体 | 相关词 | 父词 | 兄弟词 | 子词 | 关联词 |
| Smoked salmon | Gravlax,Lox,Cured salmon | Preserved fish | Smoke trout,bacalao,salt-cured sardines, pickled anchovies | Smokes salmon flatbread with creme fraise, linguini with smoked salmon and asparagus | Jewish cuisine, kosher foods | Creme fraise, bagels, capers, dill, crackers, fish knife, caviar |
建立一个受控词汇表
(1)收集内容
第一个问题应当是:“我想要组织的到底是什么?”我们发现,对此最有效的方法就是建立一个内容目录。内容目录(content inventory)是对网站上现存的所有东西以及你希望网站能够增加的所有东西的一个记录。
接下来可能还希望完成一个内容审计,这样一来不仅要统计每一个内容,还必须根据某些准则对各个内容做出评价,如冗余度、时效性和有效性。完成内容审计后,你就能全面地了解目前有些什么,将会有什么以及哪些内容真正具有价值。
(2)从尽可能多的来源收集词汇
可以先从内容入手,挑出当前主题独有的术语。还可以查看现有的分类辞典。
主题词示例
| 优选词语 | 同义词 | 缩写 | 首字母缩写 | 候选拼写方法 |
| Rock music | Rock and Roll | Rock | R&R | Rawk |
(3)定义优选词语
优选术语(preferred term)是一种在内部控制词汇表并保证所有人都能达成共识的工具,同时它也是一种了解标记过程的方法。
(4)链接同义词和近义词
(5)按主题对优选术语分组
使用卡片分类方法,抽出优选术语,组织到同类的组中。
(6)找出广义术语和狭义术语
确定每个术语最适合放在层次结构的位置。
(7)完成关联链接
问问自己,用户下一步可能想去哪里,只选择最明显和最重要的关系:
- 奶酪链接饼干
- CD链接音乐会门票
- 锤子链接钉子
- 驱动程序下载链接支持文档
(8)对选择及相应原因建立文档
为你的后来者考虑,应当以某种方式写下你已经做了什么,以便后来者可以借助你的这些经验。
3. 标签
标签即使公开的关键字。长期以来,图书管理员、科学家、技术人员不仅会把东西分类存放,还会命名关键字,以便通过搜索可以找到。Delicious是第一个允许用户为某个对象增加关键字的网站。
用户生成的内容越来越普遍,标签已经成为i额创建可拓展分类系统的唯一途径。同时,标签有助于个性化组织。
一方面是灵活的可扩展分类系统,另一方面是聚集、保存甚至推荐新项目的标记功能,二者的结合使标签成为所有Web 2.0网站的一个选择,甚至一些早期的Web网站也尽力跟踪这种技术。综合传统的分类方法,标签会更加有用。
标签类型
| 标签类型 | 示例 |
| 描述性 | city,architecture,night,skyline |
| 资源 | Book,video,photo,podcast |
| 所有权/来源 | NYTimes |
| 观点 | Tooshort,Lame |
| 自我称谓 | Me,mine,ownit |
| 人物组织 | Todo,toread |
| 演出和表演 | Squaredcircle |
标签系统的难题
冷启动的问题:Amazon第一次在网站中引入标签时,几乎没有人用它,并不是所有人都能知道该做什么。如果没有给出标签的例子,人们考虑如何描述一个给定对象时就会有困难。
对此有下面几种解决方法:
- 尽量使用对人们更有意义的标签,如材料(material)、主题(topics)、或者是任何适合网站内容的标签。
- 包含一个简要的说经,指出如何对标签域旁边的对象加标签
- 通过找出描述中与众不同的词来创建初始标签。这会让人们对于什么是标签以及标签有什么作用有所认识。
- 让公司的同事也来加标签,创建初始的示例和活动。
重复标签问题:Flickr有大量图片标注“photo”这样的标签。可以通过建议相关词、允许用户建议相关词来解决。
竞争标签问题:元数据存在于一个竞争的世界。供应者竞争着要出售他们的商品,古怪的人竞争着要把他们想入非非的怪理论告诉别人,艺术家竞争着向观众展示。注意力是发散的,钱包可能并不发散,但是它们有一定的相似性。
例如,搜索引擎的色情链接,垃圾邮件等。通过标签系统,用户可以为所欲为,而不是做你真正希望他们做的事情。