自我报告度量最为常见的一个应用是作为感知可用性(perceived usability)的一个总体测量,这是在参加者完成他们与产品的文互后给出的。这可以作为产品可用性的一个总的“晴雨表”。
1. 合并多个任务的评分
考察测试后可用性的最简单方法可能是对所有任务的自我报告数据取平均值。这是参加者留下的对产品的感知印象,这会影响他们未来对产品作出的任何决定。所以,如果想在在单一任务绩效的基础上侧量参加者所感知到的产品的易用性,那么需要把来自多个任务的自我报告数据合并起来。
然而,如果对了解最终的可用性感知感兴趣,那么建议使用下面的方法,这些方法都是在测试末尾进行一次性的测查。
2. 系统可用性量表
系统可用性量表(System Usability Scale,SUS)是由John Brooke在1986年编制的。它包括10个陈述句,参加者需要对这些句子的程度进行评分。其中一半的陈述句是正向叙述的。另一半是负向叙述的。每个句子都使用5点同意标尺。并给出了一个方法把10个评分合成一个总分(0到100分)。这种方法不需要单独考虑10句子中每个句子的评分结果,而只要考虑合并后的评分。把SUS分数看成一个百分数是非常方便的,因为它们位于一个0到100的刻度上,100代表一个完美的分数。

3. 系统可用性量表
Jim Lewis编制了任务后评分用的ASQ方法,也编制了计算机系统可用性问卷(Computer System Usability Questionnaire,CSUQ)以便在可用性研究的结束阶段对系统进行一个总体评估。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| 1. 总的来说,我对使用这个系统的容易程度感到满意 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | NA |
| 2. 这个系统使用起来简单 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 3. 我可以使用这个系统有效地完成工作 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 4. 我能够使用这个系统较快地完成工作 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 5. 我可以高效地使用这个系统来完成工作 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 6. 使用这个系统时我感到舒适 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 7. 学习使用该系统比较容易 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 8. 我认为使用该系统后工作更有成效了 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 9. 这个系统给出的出错信息清楚滴告诉我应该如何改正错误 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 10. 使用这个系统时,无论什么时候我犯了错误,我都可以容易迅速地从错误中恢复过来 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 11. 该系统提供了清除的信息(如在线帮助,屏幕上的信息以及其他文件) | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 12. 我可以容易地找到我所需要的信息 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 13. 这个系统提供的信息容易理解 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 14. 这个系统的信息可以有效地帮助我完成任务 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 15. 这个系统的信息在屏幕上组织得比较清晰 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 16. 这个系统的界面让人舒适 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 17. 我喜欢使用这个系统的界面 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 18. 这个系统具有我所期望的所有功能 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 19. 总的来说,我对这个系统感到满意 | 强烈反对 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常同意 | 〇 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | NA |
4. 用户界面满意度问卷
用户界面满意问卷(Questionnaire for User Interface Satisfaction,QUIS)是由马里兰大学的人机交互实验室(Human-Computer Interaction Laboratory,HCIL)中的一个研究小组编制的(Chin、Diehl和Norman,1998年)。
QUIS包括27个评价项目,分为5个类别:总体反应(Overall Reaction)、屏幕(Screen)、术语/系统信息(Terminology/System Information)、学习(Learning)和系统能力(System Capability)。评分是在一个10点标尺上进行,标示语随着陈述句的不同而发生变化。前6个项目(评估总体反应)没有陈述性的题干,只是一些截然相对的标示语词对(如很糟糕/很棒、困难/容易、挫败/舒适等)。
| 总体反应 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | NA | ||
| 1. | 很糟的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 极好的 | 〇 |
| 2. | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 3. | 令人受挫的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 令人满意的 | |
| 4. | 功能不足 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 功能齐备 | |
| 5. | 沉闷的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 令人兴奋的 | |
| 6. | 刻板的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 灵活的 | |
| 屏幕 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 7. 阅读屏幕上的文字 | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 8. 把任务简单化 | 一点也不 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常多 | |
| 9. 信息的组织 | 令人困惑的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常清晰的 | |
| 10. 屏幕序列 | 令人困惑的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 非常清晰的 | |
| 术语/系统信息 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 11. 系统中的术语的使用 | 不一致 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 一致 | |
| 12. 与任务相关的术语 | 从来没有 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 总是 | |
| 13. 屏幕上消息的位置 | 不一致 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 一致 | |
| 14. 输入提示 | 令人困惑的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 清晰的 | |
| 15. 计算机进程的提示 | 从来没有 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 总是 | |
| 16. 出错提示 | 没有帮助的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 有帮助的 | |
| 学习 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 17. 系统操作的学习 | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 18. 通过尝试错误探索新特征 | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 19. 命令的使用及其名称的记忆 | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 20. 任务操作简洁明了 | 从来没有 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 总是 | |
| 21. 屏幕上的帮助信息 | 没有帮助的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 有帮助的 | |
| 22. 补充性的参考资料 | 令人困惑的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 清晰的 | |
| 系统能力 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||
| 23. 系统速度 | 太慢 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 足够快 | |
| 24. 系统可靠性 | 不可靠的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 可靠的 | |
| 25. 系统趋于 | 有噪声的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 安静的 | |
| 26. 纠正您的错误 | 困难的 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 容易的 | |
| 27. 为所有水平用户进行设计 | 从来没有 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | 总是 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | NA |
5. 有效性、满意度和易用性的问卷
Arnie Lund(2001年)设计了使用的有效性(Usefulness)、满意度(Satisfaction)和易用性(Ease of Use,USE)问卷。该问卷包括30个评分项目,分为四类:有效性、满意度、易用性和易学性(Ease of Learning)。每个项目都是正向陈述(如“我会把它推荐给朋友”),用户需要在一个7点Likert标度上给出同意程度。通过分析对这个问卷的大量应用反馈,他发现在30个项目中有21个对于每个分类有更大的权重,表明它们对结果有最大的贡献。
有效性
- 它使我的工作更有效
- 它使我的工作更有产益
- 它是有用的
- 它给我更多的控制以管理生活中的各项活动
- 它使我能够更加容易地完成要做的事情
- 使用时,它节省了我的时间
- 它满足我的需求
- 它可以执行我期望它做的所有事情
满意性
- 我对它满意
- 我会把它推荐给朋友
- 使用起来有趣
- 它以我所希望的方式工作
- 它很好
- 我感到我需要拥有它
- 使用起来令人愉快
易用性
- 它容易使用
- 它操作简单
- 它是用户友好的
- 对于我需要完成的事情,它需要最可能少的步骤
- 它是灵活的
- 使用起来不费力气
- 没有书面说明,我可以使用它
- 在使用过程中,我没有发现任何不一致
- 偶尔使用和常规使用的用户都会喜欢它
- 出错时,我可以迅速且容易地恢复过来
- 每次我都可以成功地使用它
易学性
- 我可以迅速地学会使用它
- 我容易记住如何使用它
- 学起来容易
- 很快我就可以熟练使用它了
6. 生成反应卡
微软公司的Joey Benedek和Trish Miner(2002)年提出的方法以获得测试后产品的主观反应。他们的方法包括一套11张的词卡,每个卡上是一个形容词(如:新鲜的、慢的、精密复杂的、有吸引力的、有趣的、不可理解的)。其中一些词是正向的,另外一些词是负向的。参加者从中挑选出可以用来描述系统的词卡,并解释选择这些词卡的原因。
| 完整的一套反应卡:118张 | ||||
| 易接近的 | 有创造性的 | 快速的 | 有意义的 | 慢的 |
| 高级的 | 定制化的 | 灵活的 | 鼓舞人心的 | 复杂的 |
| 烦人的 | 前沿的 | 易坏的 | 不安全的 | 稳定的 |
| 有吸引力的 | 过时的 | 生气勃勃的 | 没有价值的 | 缺乏新意 |
| 可接近的 | 值得要的 | 友好的 | 新颖的 | 刺激的 |
| 吸引人的 | 困难的 | 挫败的 | 陈旧的 | 直截了当的 |
| 令人厌烦的 | 无条理得的 | 有趣的 | 乐观的 | 紧迫的 |
| 有条理的 | 引起混乱的 | 障碍的 | 普通的 | 费时间的 |
| 犯罪的 | 令人分心的 | 难以使用 | 专横的 | 过于技术化 |
| 干净利落的 | 易于使用 | 高品质 | 不可抗拒的 | 可信赖的 |
| 清除的 | 有效的 | 无人情味的 | 要人领情的 | 不能接近的 |
| 合作的 | 能干的 | 令人印象深刻的 | 私密的 | 不引人注意的 |
| 舒适的 | 不费力气的 | 不能理解的 | 品质糟糕的 | 无法控制的 |
| 兼容的 | 授权的 | 不协调的 | 强大的 | 非传统的 |
| 引人注目的 | 有力的 | 效率低的 | 可预知的 | 可懂的 |
| 复杂的 | 迷人的 | 创新的 | 专业的 | 令人不快的 |
| 全面的 | 使人愉快的 | 令人鼓舞的 | 中肯的 | 不可预知的 |
| 可靠的 | 热情的 | 综合的 | 可信的 | 未精炼的 |
| 令人糊涂的 | 精华的 | 令人紧张的 | 反应迅速的 | 可用的 |
| 连贯的 | 异常的 | 直觉的 | 僵化的 | 有用的 |
| 一致的 | 令人兴奋的 | 引人动心的 | 令人满意的 | 有价值的 |
| 可控的 | 期盼的 | 不切题的 | 安全的 | |
| 便利的 | 熟悉的 | 低消耗的 | 过分简单化的 | |
7. 测试后自我报告度量的比较
Tullis stetson(2004年)报告一项研究,在这项在线可用性研究中,他们要测量用户对网站的反应。该研究的主要目的是对几种不同的测试后问卷进行比较。他们研究了以下问卷,之前对这几个问卷的表述方式进行了一点修改,以表示是对网站的评价:
- SUS:每个问题中“系统”一词都被“网站”代替。
- QUIS:最初的三个评分项目看起来不适合对网站进行评定,所以删掉了(如“记住命令的名字和使用”)“系统“一词被“网站”代替;“屏幕”基本上被“网页”代替。
- CSUQ:“系统”或“计算机系统”一词被“网站”代替。
- 微软的产品反应卡:每个词都由一个复选框来呈现,要求参加者选择出最能描绘他们与网站交互时的形容词。他们可以自由地选择选择,词卡的数量不受限制。
- 他们自己的问卷:他们在网站可用性测试中已经使用这个问卷好几年了。该问卷包括9个正向陈述(如这个网站视觉上吸引人),网站的用户在一个7点Likert量表(从“强烈反对”到“非常同意”)上进行评价。
他们使用这些问卷在一个在线可用性研究中对两个门户网站进行评价。该研究一共包括123名参加者,每个参加者用这些问卷中的其中一个问卷对两个网站进行评估。
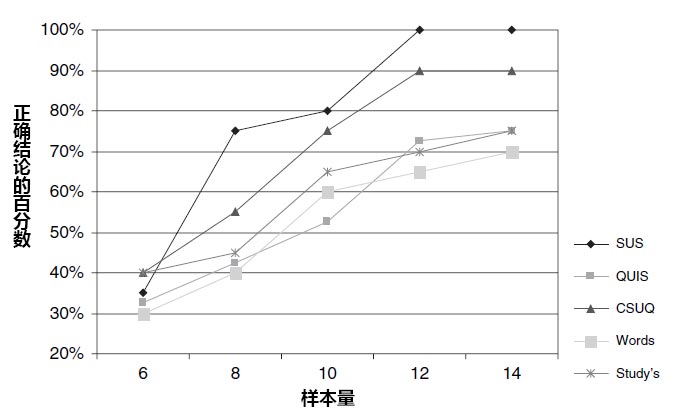
在完成问卷之前,每个参加者需要先在每个网站上完成两个任务。当研究者分析所有参加者的数据时,他们发现所有5个问卷的结果都显示出:网站1明显地比网站2得到了更好的评分。然后对不同样本t(从6-14)的数据结果进行了分析。如下图所示,在样本t为6时,只有30%到40%的参加者可以明确表示更喜欢网站1。但是当样本t为8时,发现SUS得分中有75%的参加者更喜欢网站1这个比例比通过其他任何问卷得出来的比例都要明显地高。
转载请注明:陈童的博客 » 如何进行测试后评分?