任务后评分就是让参加者在一个或多个量表上对每个任务进行评分.对每个任务进行评分就是为了对那些最难的任务有个充分的了解。
1. 易用性
可能最常用的自我报告度量就是让用户对每个任务的难易程度进行评分。
- 通常让他们在一个5点或7点量表上对任务进行评分。一些可用性专业人员更客欢使用传统的Likert量表,如“这个任务容易完成“(1=强烈反对,3=既不同意也不反对,5=非常同意)。
- 另外一些专家则更喜欢使用语义差异技术,他们使用的固定标示语为“容易/困难”。这两个技术都会使你获得参加者在任务层面上感知可用性的粗略测量。
2. 情景后问卷
Jim Lewis(1991年)编制了一套有三个题目评分量表——情景后问卷(ASQ,After-Scenario Questionnaire),目的是用来在用户完成一系列任务或一个情景任务后进行评分:
1.“我对该情景中任务完成的容易程度感到满意。”
- “我对该情境中完成任务所用的时间感到满意。”
- “在完成任务时,我对辅助性信息(在线帮助、信息、文档)感到满意。”
每个陈述都伴随着一个7点的评分量表,两端分别是“非常反对”和“非常同意”。可以计算每个问题的平均值、上-2/下-2区分数或每个任务的总分。注意ASQ中的每个问题分别涉及了可用性的3个基本方面:有效性、效率和满意度。

3. 期望测量
Albert和Dixon(2003年)提出了一个不同方法来收集每个任务后的主观反应。他们认为,对于每个任务是难还是容易,最重要的是将之与期望中的难度相比。在参加者实际完成任何任务之前,Albert和Dixon要求参加者根据他们对任务或产品的理解,对他们期望中的每个任务有多难或多容易进行评分。
在完成每个任务后,要求参加者对任务的实际难度有多大进行评分。“前面”的评分被称为期望评分,“后面”的评分被称为体验评分。对于两个评分,都使用了7点量表(1=非常困难,7=非常容易)。对于每个任务,可以计算出一个平均的期望评分值和一个平均的体验评分值,然后可以以散点图的形式呈现每个任务的这两个分数。如下图所示:
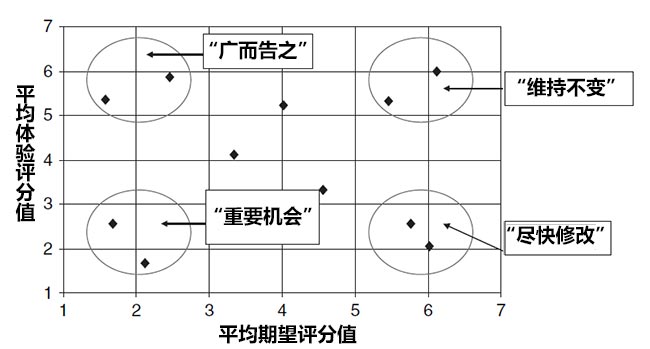
- 右下角象限是参加者认为应该容易但是实际上却很困难的任务,这可能表示用户对这些任务是最不满意的,对此用户也非常失望。这是你应该首先注意的任务,也就是为什么叫做“尽快修改”象限。
- 右上角象限是参加者认为应该容易而且实际上也确实容易的任务。这些任务运转良好。不需要去“打断”它们以免所实施的改变带来负面影响。这就是为什么会被称作“维持不变”象限。
- 左上角象限是参加者认为困难而实际上却非常容易的象限。对系统的设计者和用户来说。这都是令人愉快的意外发现。这表明你的网站或系统有助于使你的产品区别于竞争产品并脱颖而出。这就是为什么会被称作“广而告之”象限。
- 左下角象限是参加者认为困难而实际上也确实困难的任务。这里没有很大的意外,但是这可以有一些重要的改进机会。这就是为什么会被称作“重要机会”象限。
4. 可用性数量估计
Mick McGee(2004年)主张在自我报告测验中使用一个有别于传统评分量表的研究方法。
在传统的心理物理方法中,实验者会呈现一个参考刺激(如一个光源),然后要求参加者对光源的一些特征赋予一个值(例如它的亮度)。然后,呈现一个新的光源,要求参加者根据参考刺激的亮度值对新光源的亮度也赋予一个值。这种方法的关键之处之一,是要向参加者说明并要求他们在实验过程中保持同样的对应比率,即所斌予的数值比率和所感知的数量比率要相等。
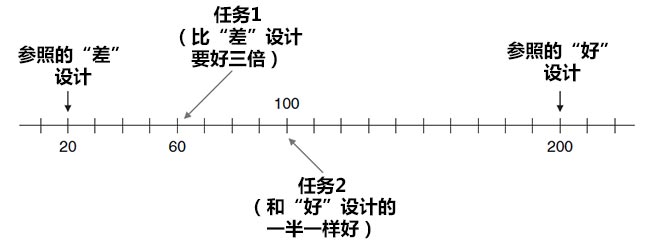
当在可用性研究中采用这种方法时,可以先给参加者提供一个参照的“好设计”和“差设计”。McGee(2004年)用了两个例子演示在登录一个网站时一个界面的好、坏两个版本。 下一步,要求参加者对参照的好设计和差设计赋予一个“可用性值”,它可以是任意一个正数。假设参加者对参照的差设计赋值为20。对参考的好设计斌值为200。然后要求参加者对所完成的任务以及该网站对该任务的支持进行判断,判断时要与参考值进行对比。例如,如果任务1比参照的差设计要好三倍,.将会得到60的值。如果任务2和参照的好设计的一半一样好,那将会得到100的值。通过这种方式,每个参加者建立了他自己的“可用性标尺”并可以用这个标尺去表达他自己的感受。
5. 任务后自我报告度量的比较
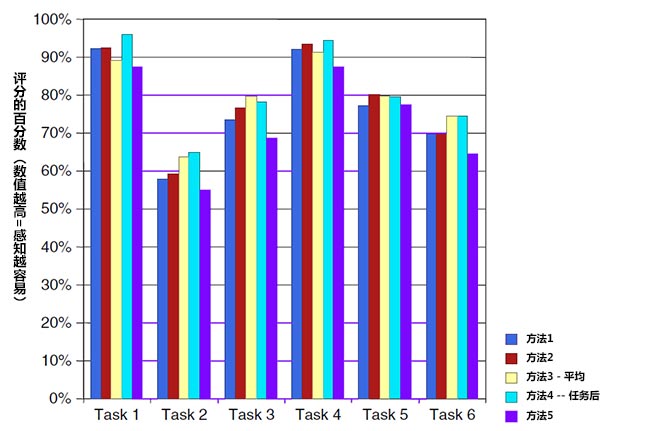
Tedesco和Tullis(2006年)在一个在线可用来性研究中比较了多种基于任务的自我报告度量。具体地说。他们运用下面5种不同的方法来获取每个任务后的自我报告评分。
方法1:“总的来说,这个任务:非常困难〇〇〇〇〇非常容易”,这是一个非常筒单的、一些可用性小组经常使用的任务后评定量表。
方法2:“请评价在这个任务中该网站的可用性:非常难以使用〇〇〇〇〇非常容易使用’,很明显,非常类似于方法1,但是强调了网站的可用性。
方法3:“总的来说。我对完成该任务的容易程度感到满意:强烈反对〇〇〇〇〇非常同意”。“总的来说,我对完成该任务所用时间的长短感到满意:强烈反对〇〇〇〇〇非常同意”,这是Lewis在ASQ(1991年)中所用的三个问题中的两个。ASQ中所问的关于辅助信息(如在线帮助)的第三个问题由于与本研究无关,所以在这里没有使用。
方法4:(在做所有的任务之前):“你期望这个任务有多困难或多容易?非常困难〇〇〇〇〇非常容易”、(在做所有的任务之后):“你发现这个任务有多困难或多容易?非常困难〇〇〇〇〇非常容易”,这是Albert和Dixon(2003年)所描述的期望测量。
方法5: “请用一个1到100之间的数字来表示该网站支持你完成这个任务的程度。记住:1表示该网站完全支持作用并且不可用。100则指该网站非常完美而且绝对不需要改进。”
一项在线研究比较了这些方法。参加者在一个在线产品上完成了查询职员信息(电话号码、地址、管理人员等)的6个任务。每个参加者只使用5个自我报告方法中的一种。总共有1131名职员参与了这个在线研究。其中至少有210人使用了各自的自我报告方法。
本研究的主要目的,是了解这些评价方法对于感知任务难度的差异是否敏感。但是研究者也想了解感知难度与任务操作数据是如何对应的。他们收集了任务时间和二分式成功数据(即:对于每个任务,参加者是否发现了正确答案以及他们花费了多长时间)。如下图所示,任务2是最难的,任务4是最容易的。
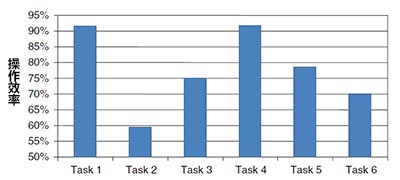
对所有方法的主观评分就平均,评分结果表示为最大可能得分的百分比。与绩效数据相似,任务2产生了最差的评分结果,而任务4的操作绩效是最好的。
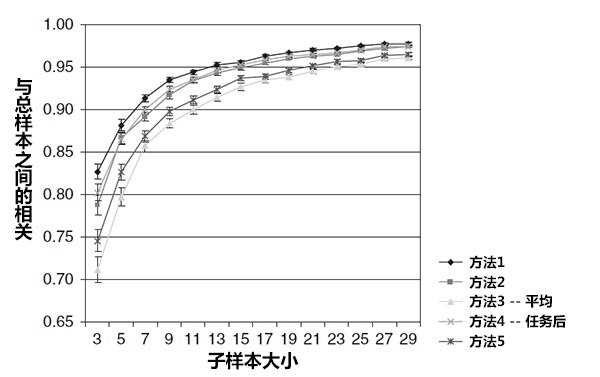
从数据中随机抽取出不同的样本量进行分析,所有这5个方法在6个任务中基本上产生了相同的模式。
子样本分析的结果标明,每种方法条件下不同大小的子样本与总样本之间的平均相关。误差值表示平均数的95%的置信区间。
转载请注明:陈童的博客 » 如何进行任务后评分?