这部分主要研究的是特定网站的搜索系统。在各种搜索系统中,对Web搜索系统的测试、用法研究和投资是最多的。为什么不好好利用这些研究成果呢?
网站需要搜索功能吗?
不要以为搜索系统可以满足用户的所有信息需求,虽然很多用户使用搜索功能,但有些用户只是想浏览内容而已。在为网站构建搜索系统之前,首先思考以下问题:
网站有足够的内容吗?要有多少内容才值得使用搜索系统?遗憾的是没有数字可以作为标准。如果网站比较像图书馆,而不像软件程序,搜索功能可能就有意义。再有就是考虑内容的数量,需要在建立和维护搜索系统以及搜索系统给用户带来好处之间取得平衡。
对搜索系统的投资和关注会不会影响导航系统?如果因为对搜索系统的关注和投资影响了导航系统,那么需要先修复导航的问题。因为它们之间是相互促进的,搜索系统能够利用设计优良的导航系统带来的各方面优点,例如受控词汇。另外,如果两个系统之间能够紧密合作,用户就能从这两种寻找工具中受益。
有时间和技术来优化搜索系统吗?搜索系统很好做,但很难做得好。如果没有时间和技术来优化它,搜索系统常常具有难以理解的搜索界面以及莫名其妙的搜索结果。如果不打算花时间把搜索系统调整到最佳状态,那就要重新考虑下是否需要搜索系统。
有更好的替代方案吗?如果网站没有搜索方面的技术专家,或者没有时间来配置搜索系统,或者没有钱购买相关的服务,则可以考虑改用网站索引。网站索引和搜索系统都可以帮助已经知道要找什么的用户。虽然网站索引要花费不少功夫,通常也是手工建立和维护,但任何懂HTML的人都可以维护。
下面的议题是决定何时网站会到达需要搜索系统的地步。
有太多信息需要浏览而搜索会有帮助时:Yahoo曾经每样东西都在那儿,很容易找。因为Yahoo和Web一样规模都相当小。使用可浏览的主题等级系统就很容易找到信息。但是事情发展得很快,Yahoo的信息系统无法满足信息请求数量的暴涨。最后,主题登记系统变得笨重而难以浏览。因此,Yahoo安装了搜索系统,作为在网站上查找信息的替代方式。如今大部分用户都使用搜索系统,而不再是浏览分类目录。
搜索系统可以帮助凝聚内容:许多企业网站或者大型公众网站的各个部分通常都是各行其是,没有元数据支持任何合理的浏览机制。如果面对这种情况,首先要做的是建立一个搜索系统,尽可能把跨部分的内容涵盖在内,这样通过搜索系统就可以解决用户寻找信息的迫切需求,不管信息是来自于哪个部门。
搜索是学习工具:通过对搜索日志的分析,可以所以有用的数据。这些数据包括用户实际想从网站得到什么,用户如何表达需求,通过这些数据可以诊断和调整网站的搜索系统以及其它许多领域。
搜索应该在那儿,因为用户希望在那儿:如果网站是个实用网站可能就值得采用搜索系统。因为很多时候用户时间有限,不想浏览网站的结构,而且认知的承载力门槛也低于想象。也许重要的是,用户走到哪儿,都以为那个小小的搜索框就会在那儿。这就是惯例的力量,没法阻挡。
搜索可以解决内容动态性带来的问题:如果网站有高度动态性的内容,应该考虑建立搜索系统。因为搜索系统可以协助每天对网站的内容做索引,可以确保用户获得高质量的内容。
搜索系统详解
搜索系统似乎很简单,有简单的输入框,输入和提交查询字符串,然后返回结果,就这样。搜索系统的内部当然不会这么简单。搜索系统包括配有索引的内容,是全部吗?如果不是,是哪些内容?索引信息都包括哪些?搜索系统包括很多算法,包括各种界面,检索和爬虫工具,对结果的排序等等。
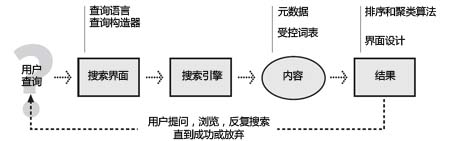
搜索系统基本解析(来自于《In Defense of Search》)
决定搜索区域
搜索区域就是网站中子网站,当用户搜索某一区域时就表明只对特定的信息感兴趣。理想情况下网站的搜索区域对应到用户的特定需求,这样可以得到更好的检索效果。把和用户需求无关的内容剔除掉,用户可以获取更少、更相关的结果。
在Dell的网站上,用户可以根据用户分类选择搜索区域,包括家庭及家庭办公、成长型企业等等。这些分类反映出该公司组织信息的方式。一般情况下,可以通过以下方式来建立搜索区域:
□ 内容种类
□ 用户
□ 角色
□ 主旨/主题
□ 地理位置
□ 日期
□ 作者
□ 部门/业务单位
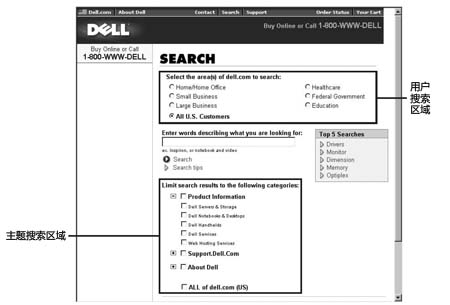
导航网页和目的地网页
大部分网站至少有两种网页:导航网页和目的地网页。目的地网页存放实际信息,导航网页可能包括主页、搜索页等。导航网页最重要的目的是指引用户到达目的地网页。
当用户搜索网站时,如果导航网页也包含在搜索结果里面,就会弄乱搜索结果。例如用户搜索Intuit公司的Quicken软件,结果会涉及下列的网页:
□ 财务产品索引页
□ 家用产品索引页
□ Macintosh产品索引页
□ Quicken产品页
□ 软件产品索引页
□ Windows产品索引页
用户可以得到正确的目的地网页,但也包括5页的导航网页。换句话说,83%的搜索结果会阻碍用户找到最有用的结果。
为特定用户做索引
如果网站采用以用户为导向的组织体系,则根据用户做切割建立搜索区域也是合理的。例如密西根图书馆有三种主要用户:议会员工、图书馆员以及市民。每一种用户对网站的信息需求都不同,再加上对对整个网站的索引,共需要四种索引。以下是“circulation”这个词在四种索引中的搜索结果:
| 索引 | 检索出的文件 | 文件检索减少的数量 |
| 统一 | 40 | – |
| 州议会区 | 18 | 55% |
| 图书馆区 | 24 | 40% |
| 市民区 | 9 | 78% |
有了搜索区域,索引间的重叠就会减少,因而增加了搜索的效果。
以主题做索引
Ameriprise Financial的网站采用松散的主题式搜索区域。例如如果要找“安全退休生活财务投资计划”的信息,可能会先选“Individual”的搜索区域。如下图所示:
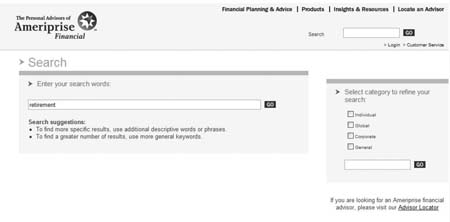
在“Individual”搜索区域下执行搜索
为新内容做索引
以时间的方式来组织内容可能是最简单的搜索区域的做法。《纽约时报》网站的高级搜索界面就是由日期来进行过滤内容的。
查询算法
搜索系统大约有40多种不同的搜索算法,很多都已经存在几十年了。如果想多学一点,可以参阅信息检索相关的数据(好的入门书是《Modern Information Retrieval》Ricardo Baeza-Yales和Berthier Ribeiro-Neo合著,Addison-Wesley出版)。
大部分的搜索算法采用模式匹配(pattern matching)的方法。也就是说,会比对用户的查询字符串和全文的索引,以寻找符合的文本字符串。评估算法的两个指标是:查全率(recall)和查准率(precision):
查准率(精度)是衡量某一检索系统的信号噪声比的一种指标,即检出的相关文献与检出的全部文献的百分比。普遍表示为:查准率=(检索出的相关信息量/检索出的信息总量)x100%。
查全率是衡量某一检索系统从文献集合中检出相关文献成功度的一项指标,即检出的相关文献与全部相关文献的百分比。普遍表示为:查全率=(检索出的相关信息量/系统中的相关信息总量)x100%。
同样,有些算法会把查询关键词根据文档相似度(document similarity)转换为查询,例如去掉“is”等停用词,留下足够代表原关键词的词汇即可。
更进一步的是,如果已经找到需要的信息,通过协同过滤法(collaborative filtering)以及引文搜索法(citation searching)拓展搜索的结果。下面的范例来自于CiteSeer,试图找出文章《Application Fault Level Tolerance in Heterogeneous Networks of Workstations》,CiteSeer会自动以多种方式查找文件:
Cited by:其它有什么论文引用了这篇文章?隐含了彼此间的相关程度
Active bibliography(related documents):此篇文章引用了在它自己的参考文献中的数据,暗示了类似的相关性
Similar documents based on text:文件会自动转换为查询字符串
Related documents from co-citation:引用的另一种形式。如果出现在不同论文的参考数据中,则它们可能有相关性

查询辅助工具
查询辅助工具(Query builder)就是可以增加查询效果的工具。常见的例子包括:
拼写检查工具:自动校正搜索术语
语音工具:扩展查询。例如可以扩展对“smith”的查询,把“smyth”的结果也包括进来
词干检索工具:用户输入一个术语(如“lodge”),然后检索出其它含有相同词干的术语(如“lodging”,“lodger”)
自然语言处理工具:可以检查查询的语法
受控词表和叙词表:在查询中包含同义,以扩展查询。