
摘要:在Web 2.0环境中发现有价值的内容变得更难,因为很多没有经验的用户提供了许多散乱的内容。在以前的研究中,人们已经证明在在线服务站点的提问回答服务版块中,利用非文本信息,如被引用的数目,支持的数目和答案的长度等,是有效评估一个问题的答案的方式。然而,这些特征可以很容易地被用户改变并不能反映用户的社会活动。在本文中,我们提出了一种新的方法来评估用户声望问题和答案之间的Co-occurrence特性,集体智慧。如果我们能够计算出用户声望,那么我们就可以估算的被引用数目少、支持率小的许多内容的价值。我们使用改良的PageRank算法计算用户声望。实验结果表明,我们提出的方法在识别这些内容中是有效、有用的。
关键词: PageRank,用户声望,共生,集体智慧。
1. 引言
有很多服务共利用集体智慧在互联网上共享电影,图片和知识。例如维基百科,YouTube,Facebook和GisikiN。这些服务都是基于人们的一同参与。这些服务的最重要的功能是找到或提供有用的数据,因此,每个服务都拥有自己的搜索引擎。然而,用户经常会看到关键字匹配内容是无关的,因而是无用的内容。
我们考虑一下韩国最大的门户网站NHN 旗下的“GisikiN”。“GisikiN”是在韩国最流行的知识共享服务网站。一旦用户提出问题,其他用户回答这个问题,形式类似于雅虎。然后,提问者选择最好的回答,其他人可以选择支持或不支持的答案以此来表达共识。但是,如果提问者没有选出最佳答案,其他用户可以选择最佳答案。近年来,一些研究试图寻找和探索内容的质量评估[1,2]。尽管如此,这个问题的研究仍然在发展的早期阶段。
在本文中,我们为找到有用的内容提出了一种新的方法来计算用户声望。我们建立了一个基于社会活动的社交网络,类似于提问和回答的形式。
本文的其余部分安排如下:第二节讨论相关的工作。我们提出的方法包括在第3节中叙述的共生特征和集体智慧。在第4节中各种建立实验、描述结果。在第5节中进行总结。
2相关工作
已经有很多研究关于分析文件超链接计算文件的重要性[3,4]。Kleinberg发现授权文件使用查询相关文件的超链接结构[3]。Brin and Page对超链接进行分类。他们认为,如果大量的文件有链接指向更重要的文档A,并且A有一个链接指向文档B,A链接比别的更重要。因此,他们基于这种想法设计了PageRank算法 [4]。然而,有一个问题在创建了一个新的文档时:即使新文件是很重要的,它可能有一个较低的等级,因为与旧的链接相比它具有较少的连结。Hotho等提出FolkRank:变种的PageRank [5]。该算法是基于更多的授权作者可以写更重要的标签的假设。他们建立了一个使用单词,作者,标签的网络,然后使用PageRank算法计算文件的重要性。
注意到有一些直接评价内容的研究。例如,[1]评估内容用基于无内容的方法,该方法包括引用次数、被支持次数、回答意见的次数。[6,7]正功能和负功能的使用率评价。 [2]用内容特征来评价文件的真实水平功能,如关键字,文件长度。然而,据我们所知,还没有已知研究用户声望研究评估用户生成的内容。我们从社会活动和合作中估计用户声望,并使用用户声望评估内容。
3用户信誉评价
3.1共生特性
我们用共生特征去计算问题和答案之间的相似性。我们使用的n-grams,这是不同于先前的工作[8],在博客主体中使用主题单词,注释分类垃圾邮件。由于有许多不规则的形式在网页文件中,标准的语言分析引擎像的演讲部分加标签者,效果不佳。首先,我们从标题、问题或答案中收集n-gram。然后,我们按以下公式计算相似性:
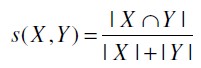
| X|文件X的n-grams的数量。 X是标题或问题,Y是的答案。
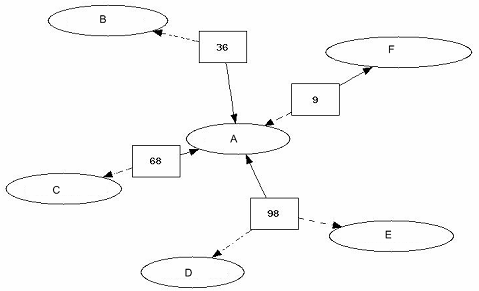
图1。包括问题和用户的社会网络。矩形代表问题和椭圆代表写下答案的来用户。在矩形中数字和在椭圆形中的字母表示唯一的ID进行识别。
3.2集体智慧
我们使用基于集体智慧的PageRank算法[4]计算用户声望。 PageRank算法使用指向其他文件的连接数计算文件的重要性。我们假设用户写的问题或答案为节点,如PageRank算法中的文档。该提出的算法类似于PageRank算法,与PageRank算法中给每个链接分配的权重不同。
在我们的算法中有两个不同的链接。一个是“链接从一个问题的一个被选择回答(例如,图1中从36到的A的链接)和另一种是“链接从问题到一未被选择的答案(例如,图1中从36到的B的链接)”。图1是一个包括问题和用户的社会网络的例子
在图1中,实线是“被选择的到答案的连接”,虚线是“未被选中的到答案”。问题有链接指向写下答案的用户。我们为了评估文件的价值而计算用户声望,如下所示:
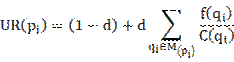
pi: 用户, qi: 问题, m(pi):问题被回答的#, c(qi):问题被回答的# f(qi) 如果选择回答为0.8,否则为0.2。
d=0.85
我们观察到,一个有用的答案不一定是由提问者选择的。这让我们考虑未选择的答案以及选择的答案。因此,我们在实验中设置所选答案为0.8和未通过选择的答案为0.2。
4实验
4.1测试数据
我们从NHN的“GisikiN”中收集测试所需的数据实验。表1显示了数据的信息。
表1. 数据信息

4.2利用集体智慧的用户声望
我们使用公式(2)进行第一个实验。表2列出了排名前10的用户的声望。
在表1中,我们可以看到根据等式(2)拥有很高声望的用户倾向于有更多的答案被选中。然而,我们注意到,user6(U6)排在第6位,虽然相较于其他人来说他有较少的答案被选中,更多的答案未被选中。这是因为我们分配0.2的权重给未选中的答案。
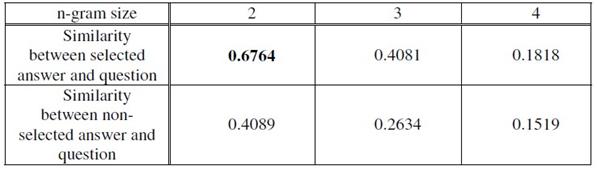
为了改善这个缺点,我们在问题和答案中用N-gram共生特征计算内容相似性。我们使用标题和问题和答案的正文和答案。选择合适的n值,我们计算不同的n的相似性。表3显示了被选择的答案比用2-gram尺寸得出的未被选择的答案具有更高的相似值。这导致我们使用bi-gram计算它们之间的相似性。
表2. 我们使用公式(2)进行实验1。需要注意的是’用户’是写下答案的人,“声望”是用户声望,选择“被选择的答案的数目,“无选择”是未被用户选择的答案的数目。
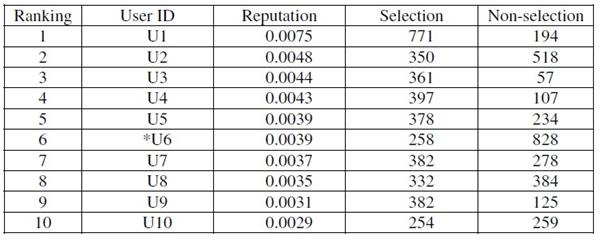
表3. 根据n-gram的大小的问题答案相似性。从实验的结果,我们使用2-gram去计算问题和答案之间的相似性。
计算相似性后,我们修改的用户声望方程如下:
![]()
其中,S()是使用共生特征的问题-答案相似性。我们使用公式(3)进行额外的实验。在表4实验2中,我们注意到相比与实验1,因为使用的问题-答案相似性,U1的声望增加,而U6的声誉下降。由此可见问题-答案相似性能有效的比较非文本特征,如答案数量。
我们引入另一个不错的特征来评估从社会网络的内容:匿名读者的推荐数目。无论提问者如何选择答案,一个好的答案会收到了很多推荐。我们用推荐的比例代替推荐的数字作为标准,我们给被选择的答案、未被选择的答案、自我回答以不同的权重,因为自我回答能伪造用户的声望,我们给它分配一个低利率。从结果来看,我们可以知道,有许多未被选中的答案和低的推荐数的用户,比如U6,排名比试验2大大落后了。
表4. 我们使用等式(3)进行实验2。需要注意的是’用户’是写下答案的人,“声望”是用户声望,选择“被选择的答案的数目,“无选择”是未被用户选择的答案的数目。
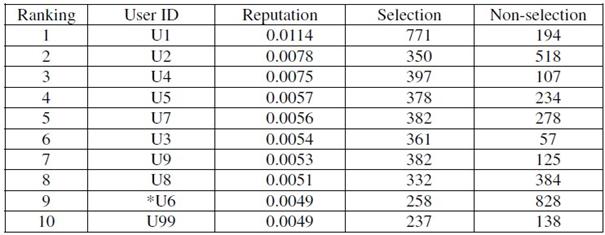
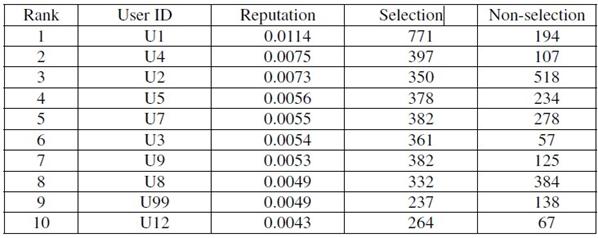
表5表示实验3的结果。注意,U6不存在在前10名用户中。U12新进入排名。表5. 我们使用公式(4)进行实验3。需要注意的是’用户’是写下答案的人,“声望”是用户声望,选择“被选择的答案的数目,“无选择”是未被用户选择的答案的数目。
5结论
Web 2.0强调用户参与。在社交网络中的用户参与是用户声望有效评判标准。在本文中,我们提出了一种新的方法利用共生的特征和集体智慧来计算用户声望以选择被给出问题的更佳答案。我们把NHN公司的“GisikiN”作为样本网站。我们定义在GisikiN中的社交网络使用问题和写下答案用户。我们对来自于GisikiN的数据进行实验测试,结果表明我们所提出的方法是有效的。我们所提出的方法在评估由用户给定的问题的答案时有良好表现,在今后的工作中我们将继续发展扩大的添加非文本特征的方法。
鸣谢。这项工作是由IT研发计划MKE/ IITA2008-S-024-01支持的。
(翻译 12S017025 郭光)
转载请注明:陈童的博客 » 基于Co-occurrence特征和集体智慧的用户声望评估



